T4 - People and data#
Modeling without data is like riding a bicycle while blindfolded – rarely dull, but often you don’t get to where you want to go. This tutorial shows how to use data with Covasim, and gives a brief introduction to people, populations, and contact layers.
Click here to open an interactive version of this notebook.
Data requirements#
Covasim is intentionally designed to be flexible with data requirements, acknowledging that some settings have large amounts of data, while others have very little. There are, however, some minimum data requirements if a real-world context is being modeled (as opposed to a theoretical exploration). These are:
Population size: To interpret results correctly, you need to know what the correct denominator is. Typically this is the city or country you’re modeling, but sometimes it’s not as simple as it may seem, especially early in an epidemic when cases tend to be concentrated near the source of the outbreak.
Deaths per day: Often considered to be the most reliable source of data, since deaths tend to be under-reported less than infections; however, significant under-reporting can still occur, so always treat reported deaths as the lower limit of the true value.
Diagnosed cases per day: Diagnosed cases are the most responsive measure of the epidemic conditions; however, they are dependent on both the number of infections and the testing rate. In settings with low or highly variable rates of testing, they may not be especially reliable.
In addition to these essential data requirements, several other pieces of data are useful to have. These are:
Seroprevalence: Although seroprevalence rates wane over time, they are generally a more reliable indicator of total infections than diagnosed cases.
Tests per day: The number of tests can be used directly in the
test_numintervention (see Tutorial 5), and is very useful for interpreting diagnoses data.Vaccinations per day: In locations with high vaccination rates, understanding when the vaccines were rolled out (and with which vaccines) is important for estimating current immunity levels.
Policy interventions: While changes in transmission can often be seen directly in the data on cases and deaths, at minimum it is a useful sanity check to see if these changes line up with changes in policy such as mobility restrictions or mask mandates.
Demographic data#
Covasim includes pre-downloaded data on country (and US state) age distributions and household size distributions. As we saw in Tutorial 1, you can load these data simply by using the location parameter. You can show a list of all available locations with cv.data.show_locations(). The data themselves are simply a set of dictionaries, and these can be modified directly; for example, to add a custom age distribution for Johannesburg would look like this:
# Note data format and key names!
joburg_pop = {
'0-9': 286620,
'10-19': 277020,
'20-29': 212889,
'30-39': 161329,
'40-49': 104399,
'50-59': 51716,
'60-69': 36524,
'70-79': 22581,
'80+': 7086,
}
cv.data.country_age_data.data['Johannesburg'] = joburg_pop
You can then use these data via sim = cv.Sim(location='Johannesburg').
Epidemiological data scrapers#
Covasim includes a script to automatically download time series data on diagnoses, deaths, and other epidemiological information from several major sources of COVID-19 data. These include the Corona Data Scraper, the European Centre for Disease Prevention and Control, and the COVID Tracking Project. These scrapers provide data for a large number of locations (over 4000 at the time of writing), including the US down to the county level and many other countries down to the district level. The data they download is already in the correct format for Covasim.
Note: These data sources are frequently updated, and some may no longer work. Please contact us at info@covasim.org if you’re having trouble.
Data input and formats#
The correct input data format for Covasim looks like this:
[1]:
import pandas as pd
df = pd.read_csv('example_data.csv')
print(df)
date new_diagnoses new_tests new_deaths
0 2020-03-01 1 24 0
1 2020-03-02 3 22 0
2 2020-03-03 2 15 0
3 2020-03-04 8 40 0
4 2020-03-05 20 38 0
5 2020-03-06 9 61 0
6 2020-03-07 6 43 0
7 2020-03-08 13 98 0
8 2020-03-09 6 93 0
9 2020-03-10 25 170 0
10 2020-03-11 28 368 0
11 2020-03-12 27 437 0
12 2020-03-13 22 291 2
13 2020-03-14 43 328 0
14 2020-03-15 76 1147 0
15 2020-03-16 65 1438 1
16 2020-03-17 88 1209 0
17 2020-03-18 86 1269 0
18 2020-03-19 115 1195 1
19 2020-03-20 51 529 0
20 2020-03-21 55 482 3
21 2020-03-22 95 1106 2
22 2020-03-23 74 471 1
23 2020-03-24 63 438 4
24 2020-03-25 178 1111 2
25 2020-03-26 83 621 1
26 2020-03-27 140 1059 2
27 2020-03-28 137 951 1
28 2020-03-29 150 964 0
29 2020-03-30 144 1058 1
30 2020-04-03 145 1058 1
31 2020-04-11 0 0 1
The data can be CSV, Excel, or JSON format. There must be a column named date (not “Date” or “day” or anything else). Otherwise, each column label must start with new_ (daily) or cum_ (cumulative) and then be followed by any of: tests, diagnoses, deaths, severe (corresponding to hospitalizations), or critical (corresponding to ICU admissions). While other columns can be included and will be loaded, they won’t be parsed by Covasim. Note that if you enter a
new_ (daily) column, Covasim will automatically calculate a cum_ (cumulative) column for you.
Note: Sometimes date information fails to be read properly, especially when loading from Excel files via pandas. If you encounter this problem, see Tutorial 10 for help on fixing this.
This example shows how a simulation can load in the data, and how it automatically plots it. (We’ll cover interventions properly in the next tutorial.)
[2]:
import covasim as cv
cv.options(jupyter=True, verbose=0)
pars = dict(
start_day = '2020-02-01',
end_day = '2020-04-11',
beta = 0.015,
)
sim = cv.Sim(pars=pars, datafile='example_data.csv', interventions=cv.test_num(daily_tests='data'))
sim.run()
sim.plot(['cum_tests', 'cum_diagnoses', 'cum_deaths'])
Covasim 3.1.7 (2026-02-18) — © 2020-2026 by IDM
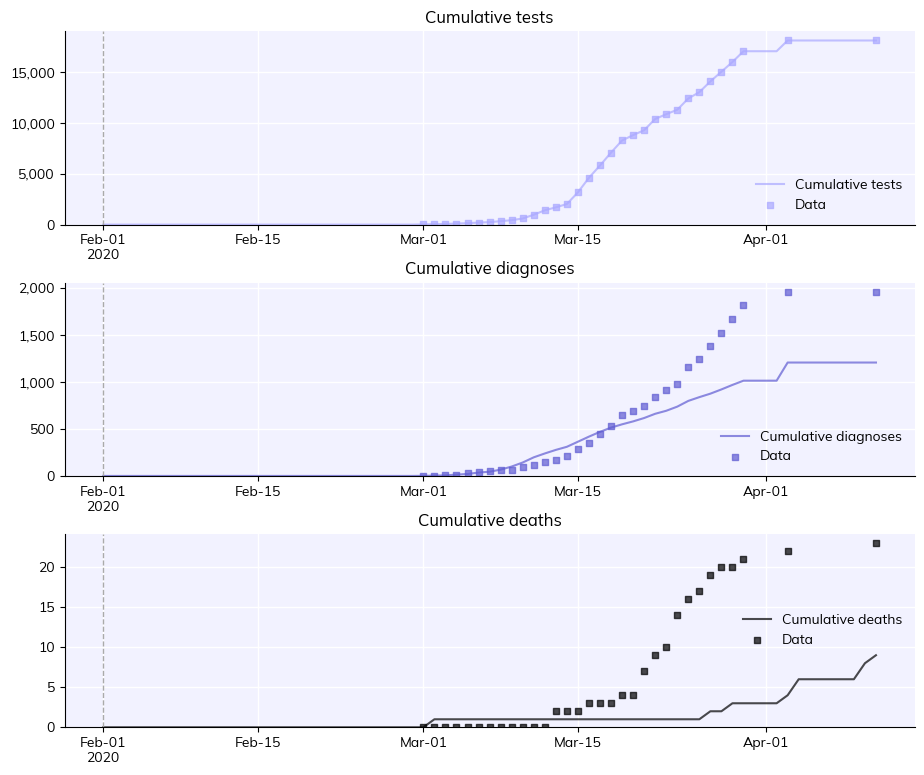
As you can see, this is not a great fit to data – but we’ll come to calibration in Tutorial 7.
People and contact network layers#
How people work#
Agents in Covasim are contained in an object called People, which contains all of the agents’ properties, as well as methods for changing them from one state to another (e.g., from susceptible to infected).
Agents interact with each other via one or more contact layers. You can think of each agent as a node in a mathematical graph, and each connection as an edge. By default, Covasim creates a single random contact network where each agent is connected to 20 other agents, completely at random. However, this is not a very realistic representation of households, workplaces, schools, etc.
For greater realism, Covasim also comes with a “hybrid” population option, which provides a more realism while still being fast to generate. (It’s called “hybrid” because it’s a combination of the random network and the SynthPops network, described in Tutorial 11, which is much more realistic but requires a lot of data and is computationally intensive.) The hybrid option provides four contact layers: households 'h', schools 's', workplaces 'w', and
community interactions 'c'. Each layer is defined by (a) which agents are connected to which other agents, and (b) the weight of each connection (i.e., transmission probability). Specifically:
Households are small clusters, usually 2-5 people (depending on country), consisting of a wide variety of ages; this setting has high transmission probability
Schools are split into classrooms, usually about 20 students each, of students aged 6–22; this setting has medium transmission probability
Workplaces are clusters of about 5-20 people, aged (approximately) 22-65; this setting has medium transmission probability
Community contacts (representing parks, restaurants, transport, places of worship, etc.) are estimated as 20 random contacts per day; this setting has low transmission probability
Loading population data#
Note that for most countries, you can load default data (age distribution and household size, both from the UN) by using the location keyword when creating a sim. For example, to create a realistic (i.e. hybrid) population 10,000 people for Bangladesh and plot the results, you would do:
[3]:
pars = dict(
pop_size = 10_000, # Alternate way of writing 10000
pop_type = 'hybrid',
location = 'Bangladesh', # Case insensitive
)
sim = cv.Sim(pars)
sim.initialize() # Create people
fig = sim.people.plot() # Show statistics of the people
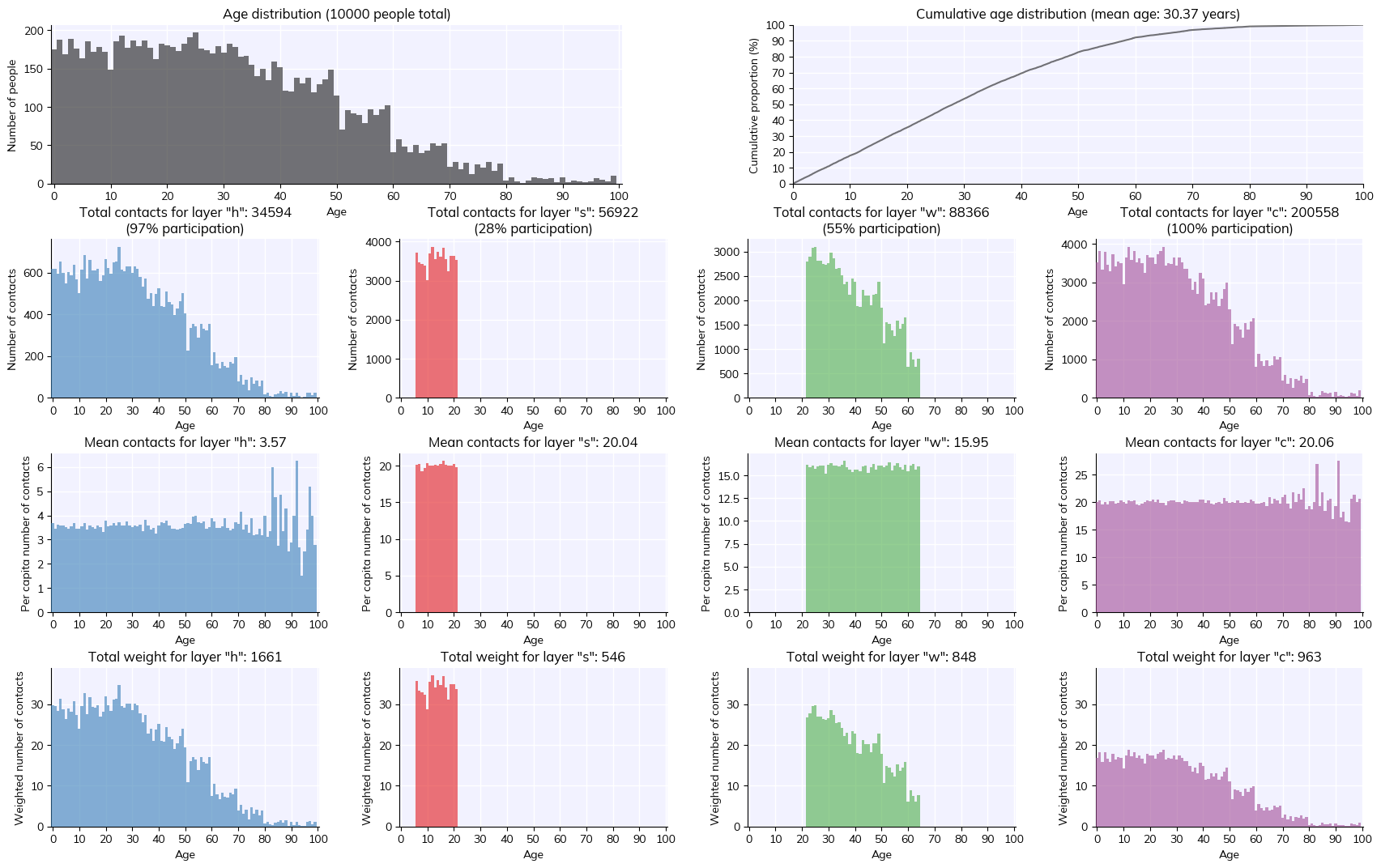
Note: For an explanation of population size, total population, and dynamic rescaling, please see the FAQ.
Saving and loading people#
Since creating populations can be slow, and since deleting people is a bit mean, sometimes you want to save the population to work with it later. To do this, initialize the people, save them, then load them again. (This example also illustrates how you can use sc.timer() to check how long a block of code takes.)
[4]:
import sciris as sc # We'll use this to time how long each one takes
pars = dict(n_agents=50e3, pop_type='hybrid')
with sc.timer('creating'):
sim1 = cv.Sim(pars).init_people()
sim1.people.save('my-people.ppl')
with sc.timer('loading'):
sim2 = cv.Sim(pars, popfile='my-people.ppl').init_people()
creating: 0.502 s
loading: 92.6 ms
It’s about twice as fast to load a population than create one, but whether this will actually matter to you depends on the population size and the length of the simulation.